2024/06/01: This is the official project site migrated from http://www.umich.edu/~ywchao/semantic_affordance/. That address was originally printed in the CVPR'15 publication but can no longer host the site.
Mining Semantic Affordances of Visual Object Categories
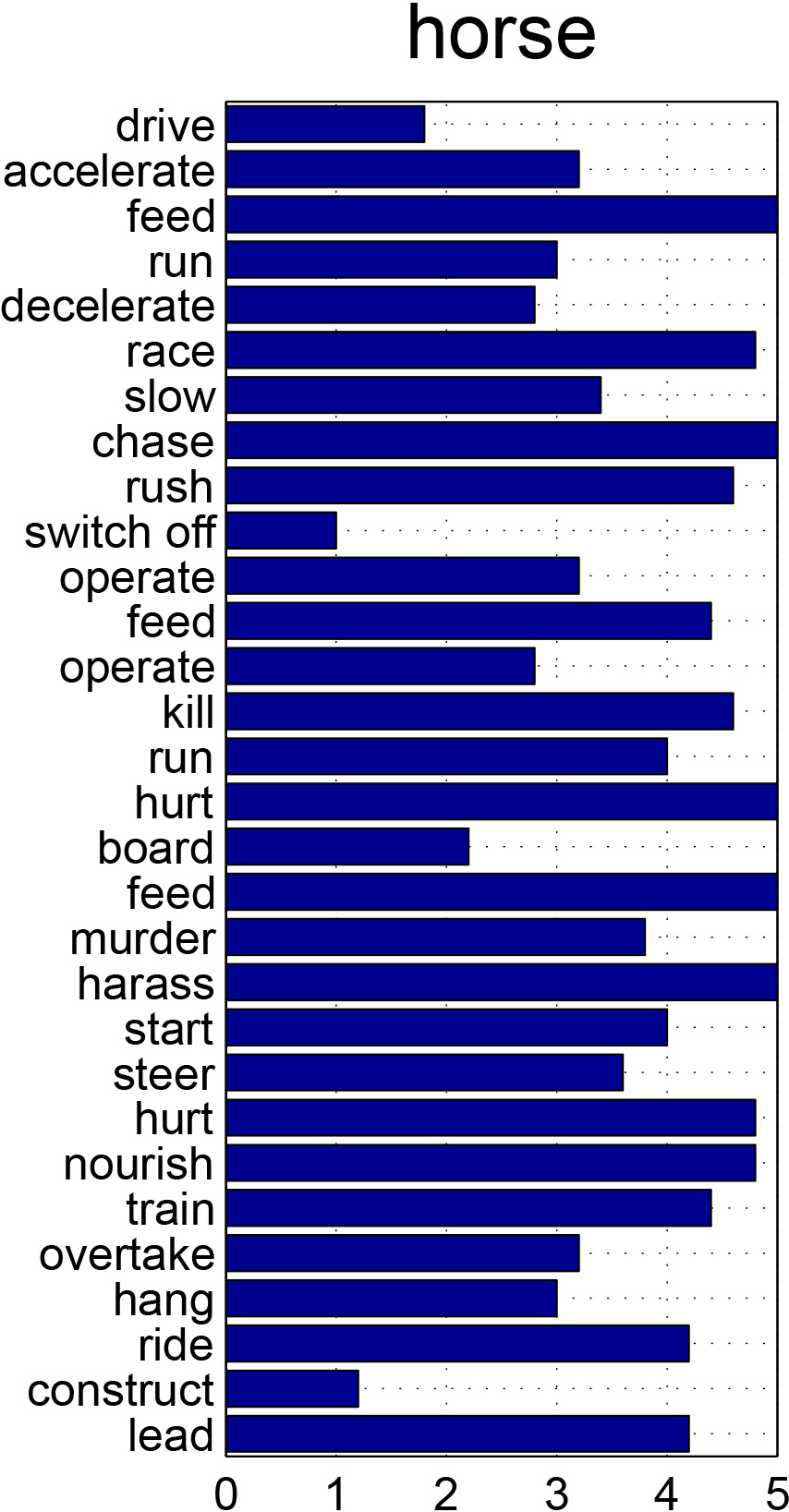
Abstract
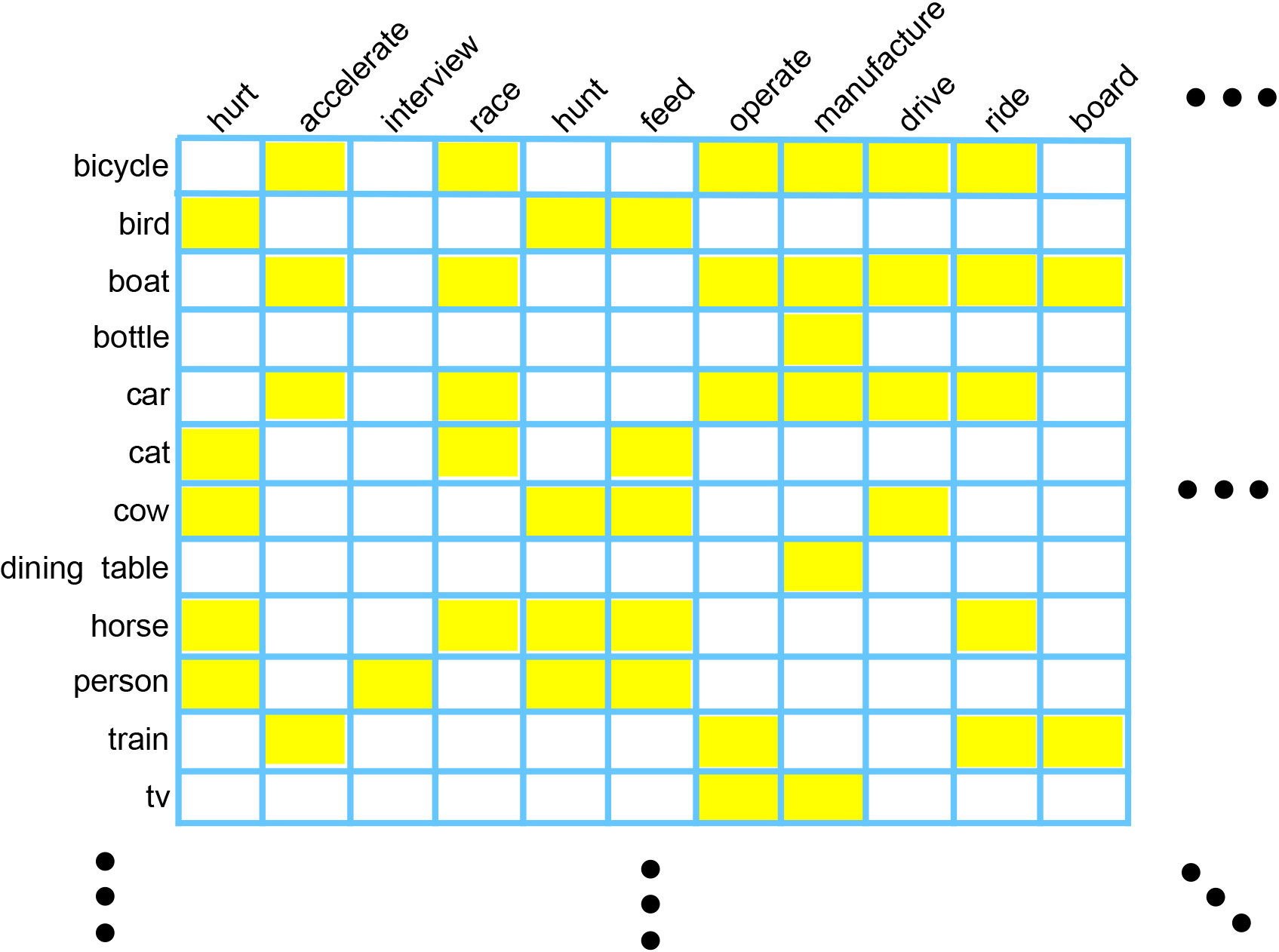
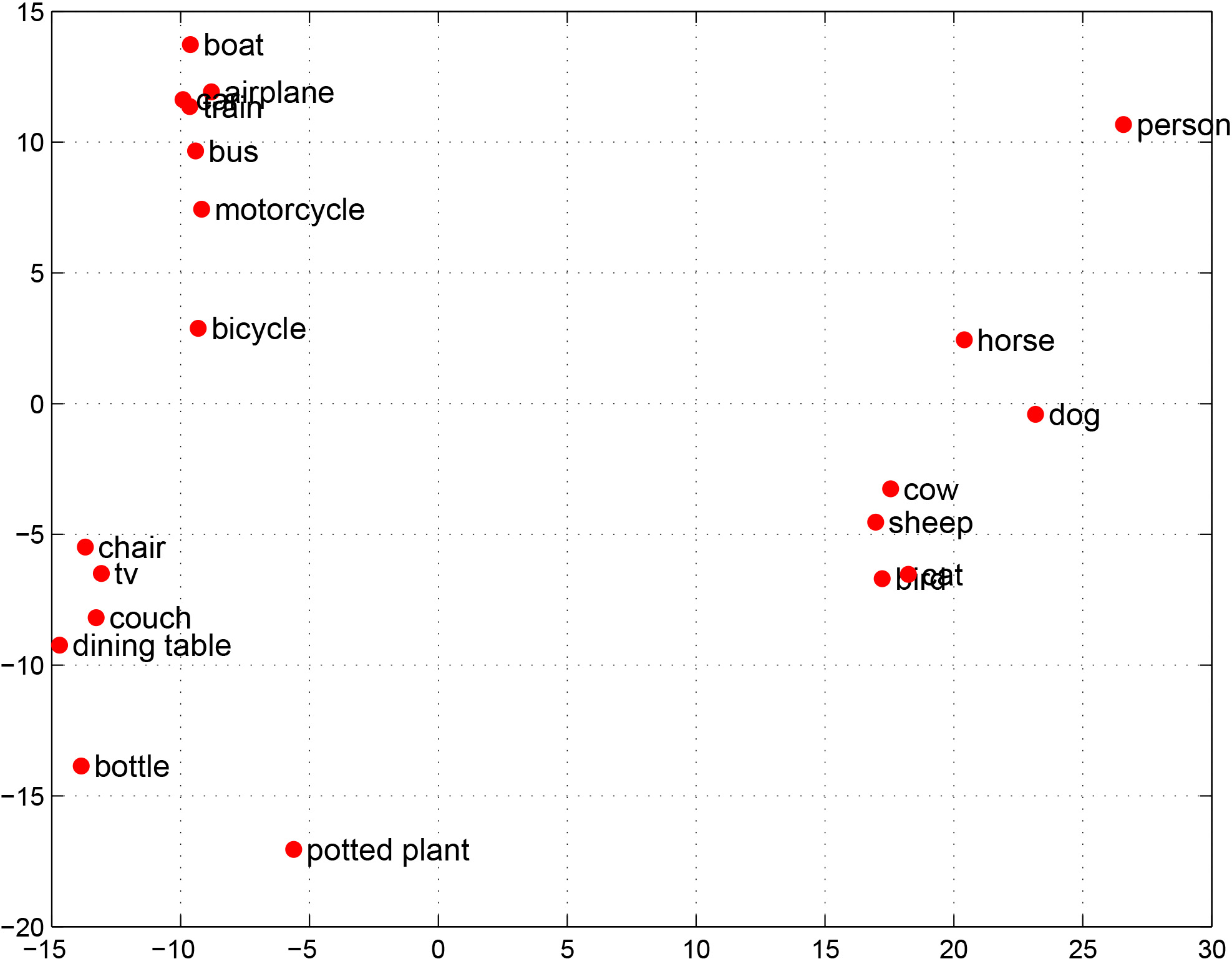
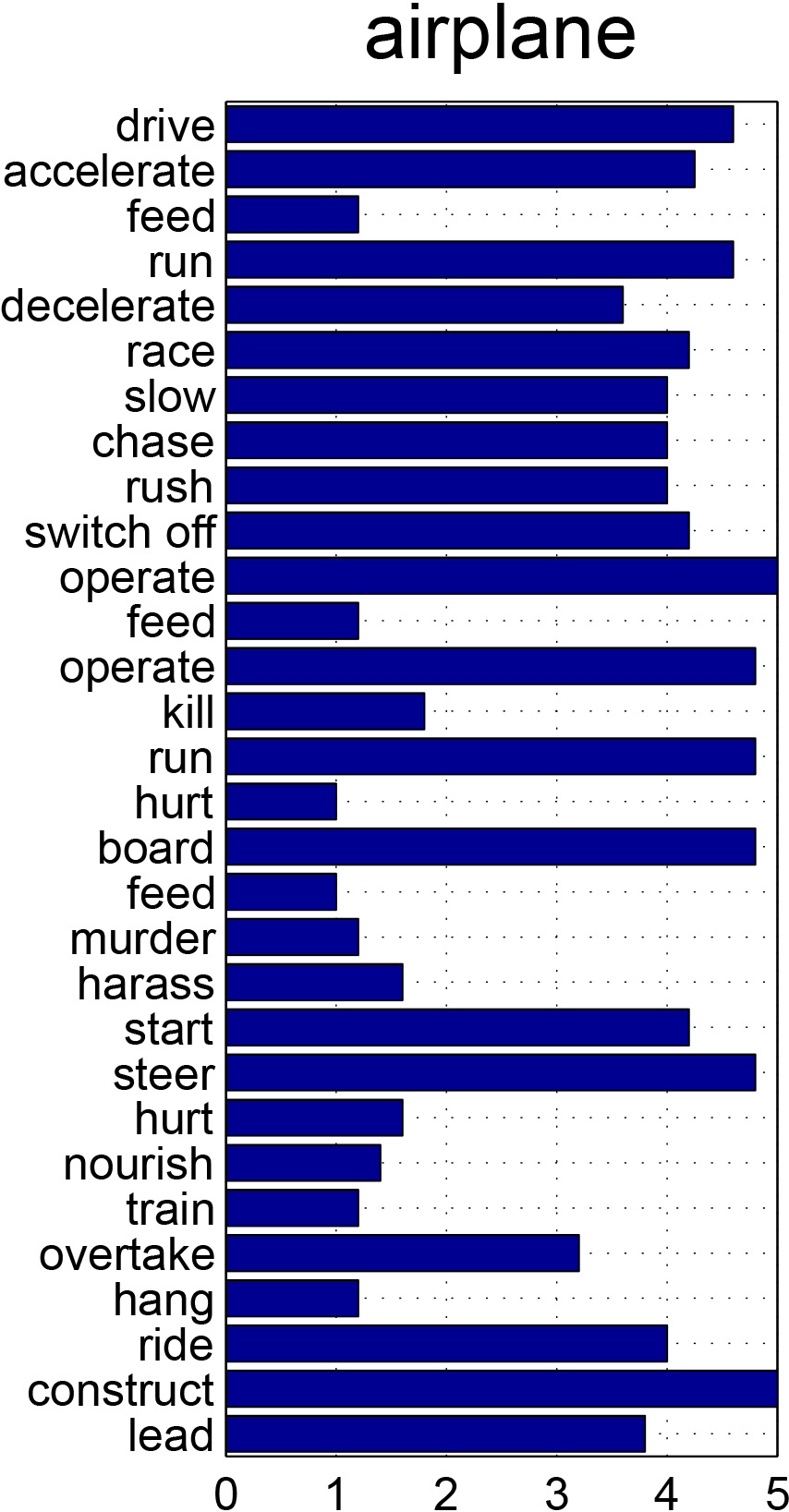
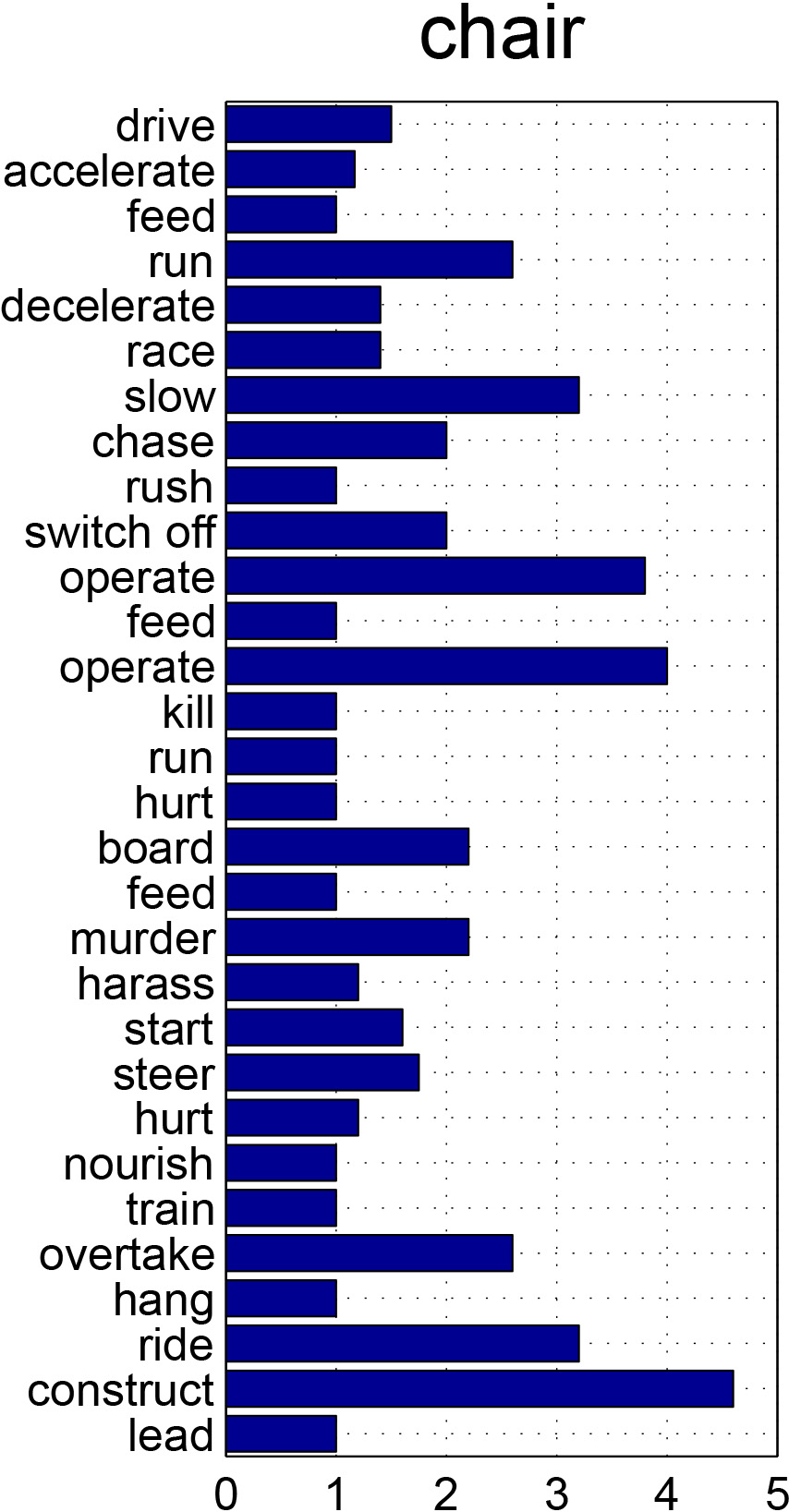
Affordances are fundamental attributes of objects. Affordances reveal the functionalities of objects and the possible actions that can be performed on them. Understanding affordances is crucial for recognizing human activities in visual data and for robots to interact with the world. In this paper we introduce the new problem of mining the knowledge of semantic affordance: given an object, determining whether an action can be performed on it. This is equivalent to connecting verb nodes and noun nodes in WordNet, or filling an affordance matrix encoding the plausibility of each action-object pair. We introduce a new benchmark with crowdsourced ground truth affordances on 20 PASCAL VOC object classes and 957 action classes. We explore a number of approaches including text mining, visual mining, and collaborative filtering. Our analyses yield a number of significant insights that reveal the most effective ways of collecting knowledge of semantic affordances.
Paper
Mining Semantic Affordances of Visual Object Categories.
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
[pdf] [poster] [bibtex]
Dataset

Affordance labels for 91 MS COCO object categories.
Source Code

GitHub repo that holds the source code for reproducing the empirical results.
Contact
Send any comments or questions to Yu-Wei Chao: ywchao@umich.edu.
Last updated on 2015/06/15